
鸟巢虐我千百遍,我爱鸟巢如初恋 回看2年前做奥运绘座的收获、成长,希望用一篇文章串联起跟绘座相关的全部。2019年5月底,从马蜂窝离职加入阿里。因为自己对图形、动画非常感兴趣加上之前在这一方向上的经验,能支持奥运赛事的大型场馆座位数字化也就是座位图对我来说非常有吸引力,在这里会遇到非常多的挑战,一定会有所成长、收获。加之这可是奥运啊~~这可是阿里啊~ 使命感、荣誉感让我非常憧憬
瑞士达沃斯,2017年1月,阿里巴巴集团正式成为国际奥委会(IOC)全球合作伙伴,成为“云服务”和“电子商务平台服务”的官方合作伙伴。
2018年10月,IOC、北京冬奥组委和阿里巴巴共同参与了奥运智慧票务项目立项会议,会上阿里巴巴正式承接了奥运智慧票务系的构建和服务工作。
我所在的团队就是奥运票务系统产研团队,我的主要职责是场馆座位图的开发。
这是22年冬奥闭幕式前夕,负责奥运会票务事务的国际奥委会电视转播和市场开发部部长提莫·鲁梅在接受媒体采访时盛赞北京冬奥智慧票务。
我们以一个座位为视角,从生产、售卖到履约的生命周期来看:
座位生产阶段: 画座;北京13个场馆的座位图数字化。
也就是票房规划,在这一阶段要在场次级别的座位图上设置票档、票价、锁座、排序、隔排隔座等
售卖阶段将会有不同的渠道对场次级别进行售卖:
1. 大客户: 为奥运赛事的合作伙伴分配座位,通常一个客户可能分配上百个座位。
2. Ticket Boxing: 奥运赛事期间线下面向公众的售卖渠道
3. web端: 赛事开始前公众的选票抽签
打印出一张票,票上标识出座位排座信息、价格信息,观赛人拿着这张票通过闸机紧凑观赛
架构设计 - 参考、借鉴,结合当前业务场景设计一套方便拓展、稳定、高效的一个渲染框架,最终取名ASeat
全力支撑奥运2022冬奥 - 物理绘座、票房规划(场次座位图)、实时售卖
赋能亚运、反哺大麦
提效 - 开发提效,运营提效
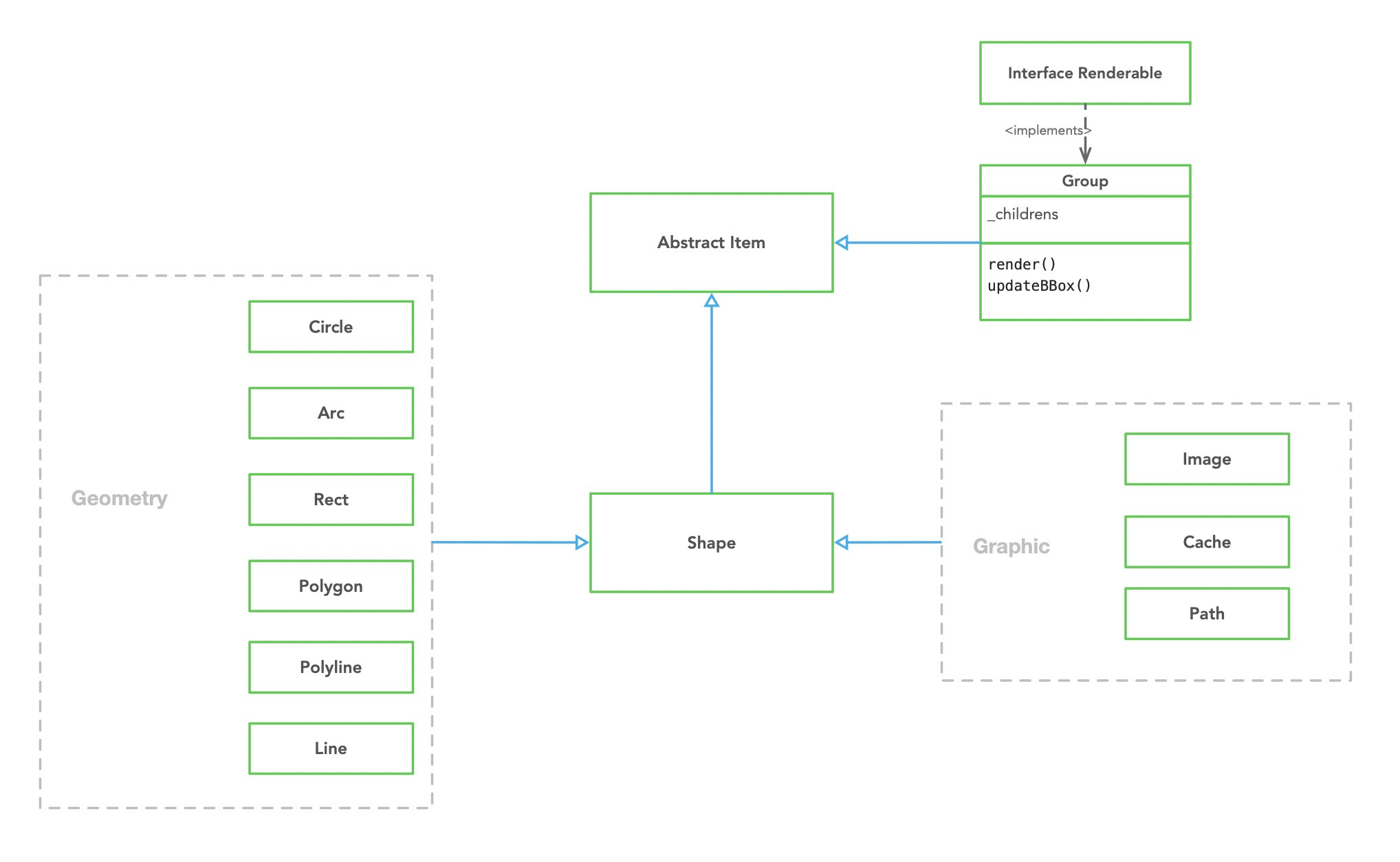
渲染引擎是重中之重,一切的业务都建立在渲染引擎基础之上。早在初期设计阶段和大麦的不断碰撞,以及参考seatIo、ticketMaster ,我们确立了渲染引擎的核心模块都有哪些,职责是什么:


核心模块设计理念
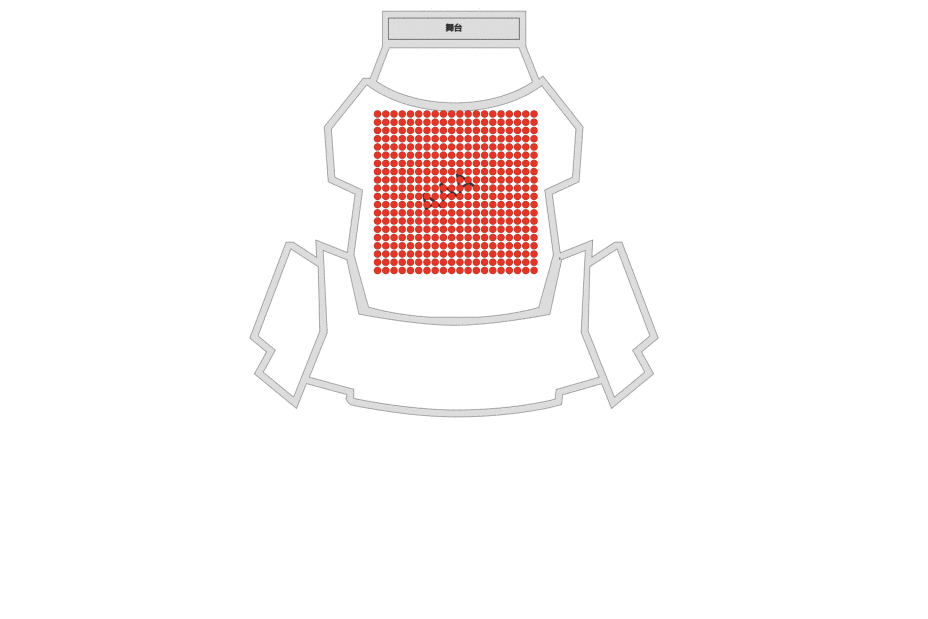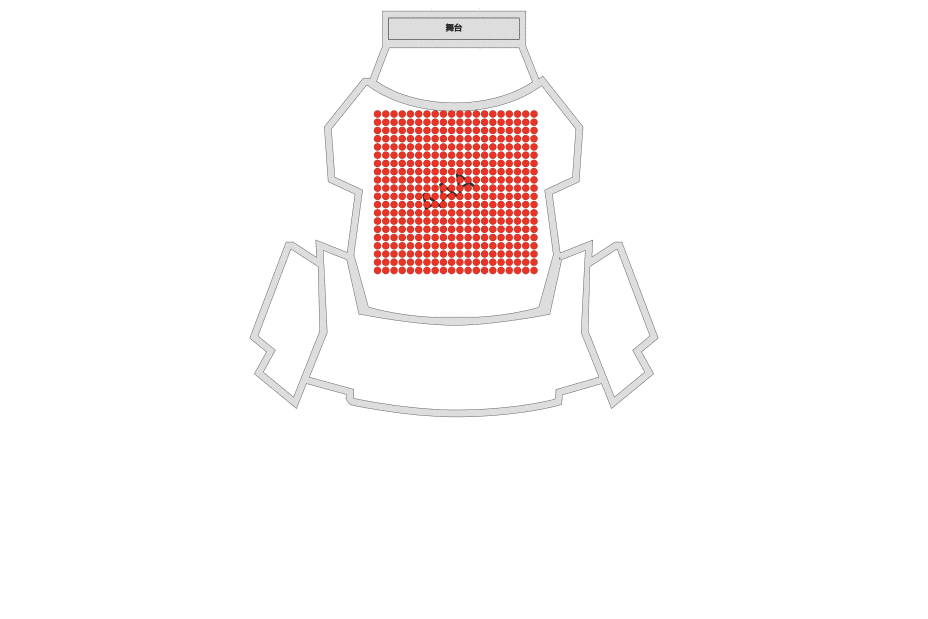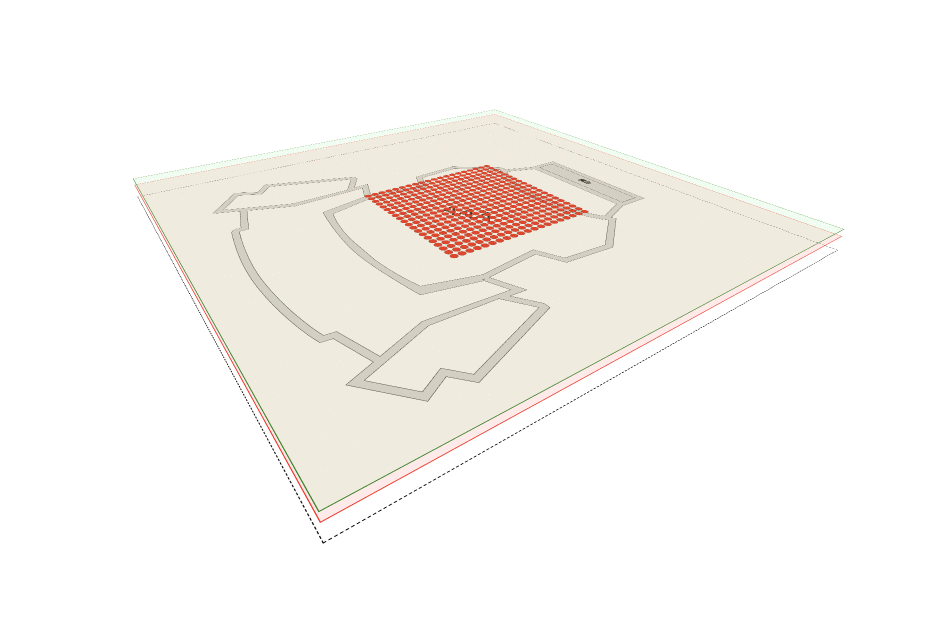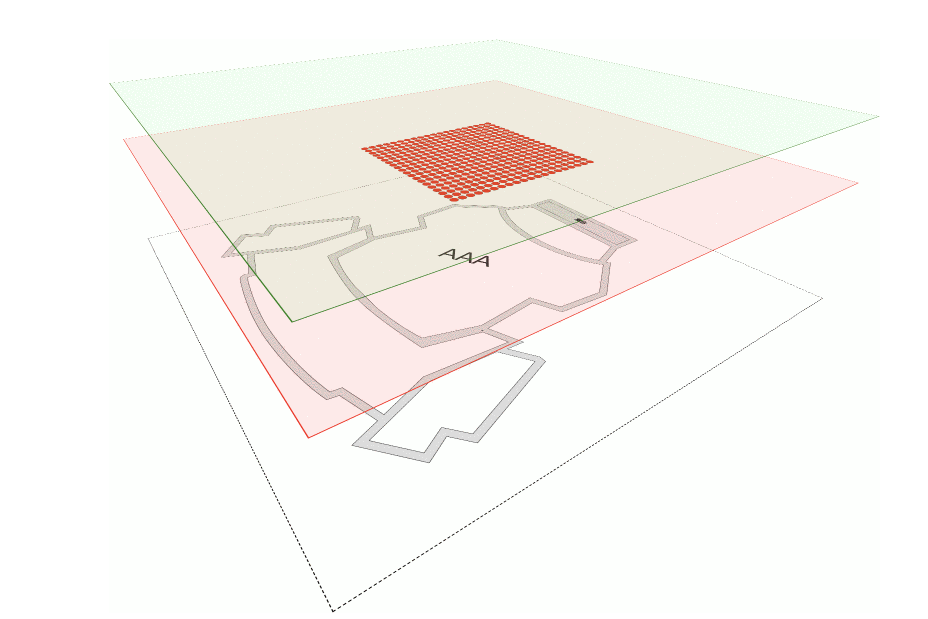
根据业务特点和定位,Aseat采用multiple layer的设计,如SVG底图、座位、选座的框/线等都个为单独的Layer。根据场景和操作频次multiple layer可减少没必要的渲染。 - Layer自己持有render方法,render由当前Layer使用了哪种renderEngine决定,如canvasLayer由canvasRender负责渲染那么就是时候用canvas context(‘2d’)负责渲染,当然canvasLayer不一定非要用cavnasRender负责渲染,可以替换成pixiRender。 由使用者决定何时render,render哪个Layer。 Layer座位Items的容器,具备Items的CURD、render、hitTest等能力。
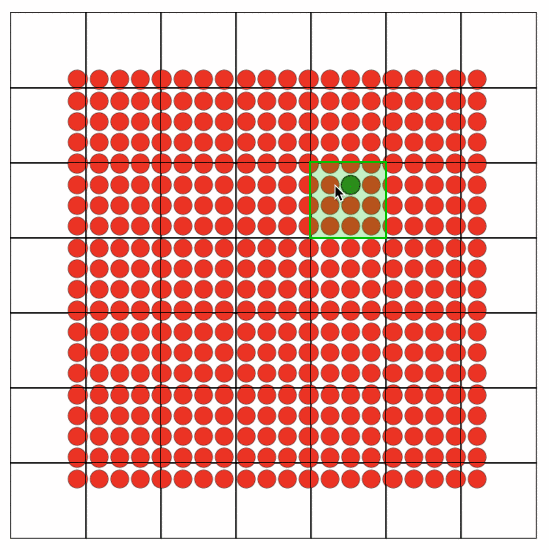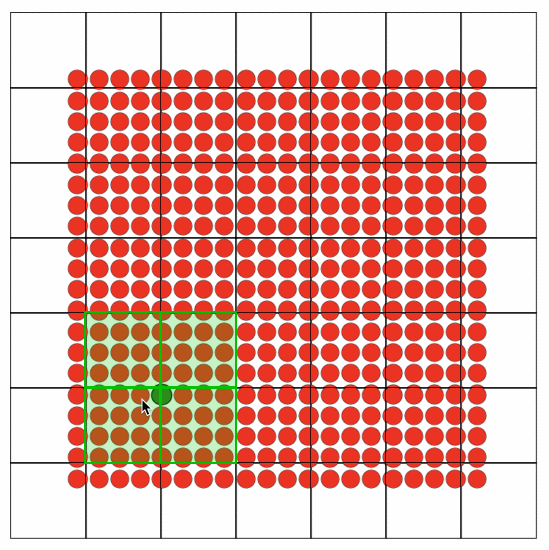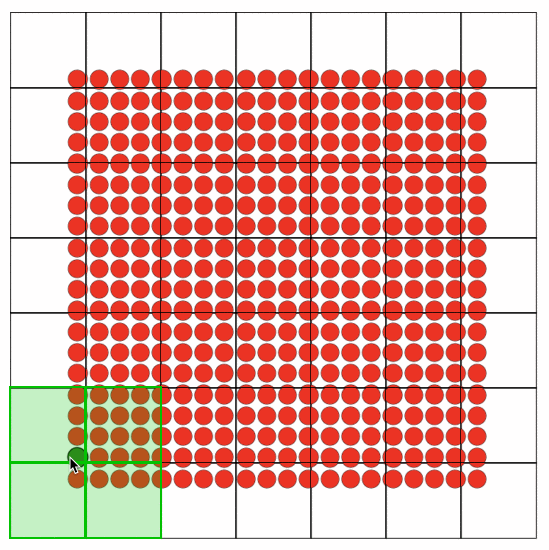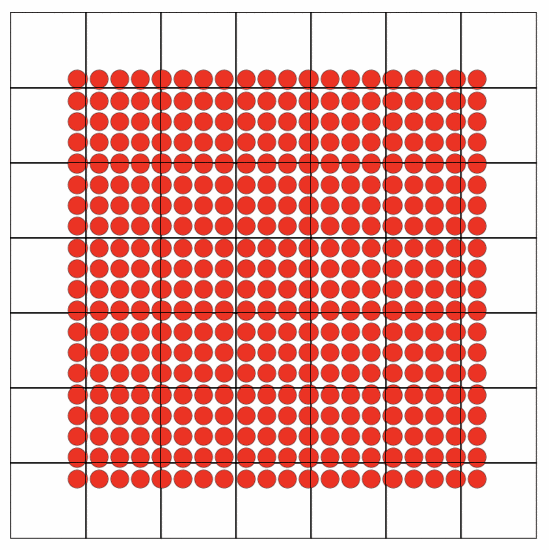
这里借鉴了大麦历史经验,抽象出canvasGridLayer,其中最核心的思想是切片,分而治之,解决了最大的问题:渲染性能。在面对动不动就需要绘制几万+座位的场景下,如果把这几万个座位放到一个Canvas中绘制,每一帧的绘制浏览器都在骂娘。把一个canvas,拆成多个grid每个grid即一个canvas,需要render的grid去render,不需要的grid就不用render。如下图所示:为方便演示,grid size 为100x100,开了chrome Paint flashing。可看到hover的Seat只有相关的grid 才发生了painting。
如下伪代码实现一个自定义Item
import { Item, Group } from "@alife/aseat-core";
export default class Seat extends Group {
...
public setAttrs(attrs: object): void {
super.setAttrs(attrs);
this._children.push(new Arc(attrs[0]));
this._children.push(new Arc(attrs[1]));
this._children.push(new Text(attrs[2]));
}
...
}

|
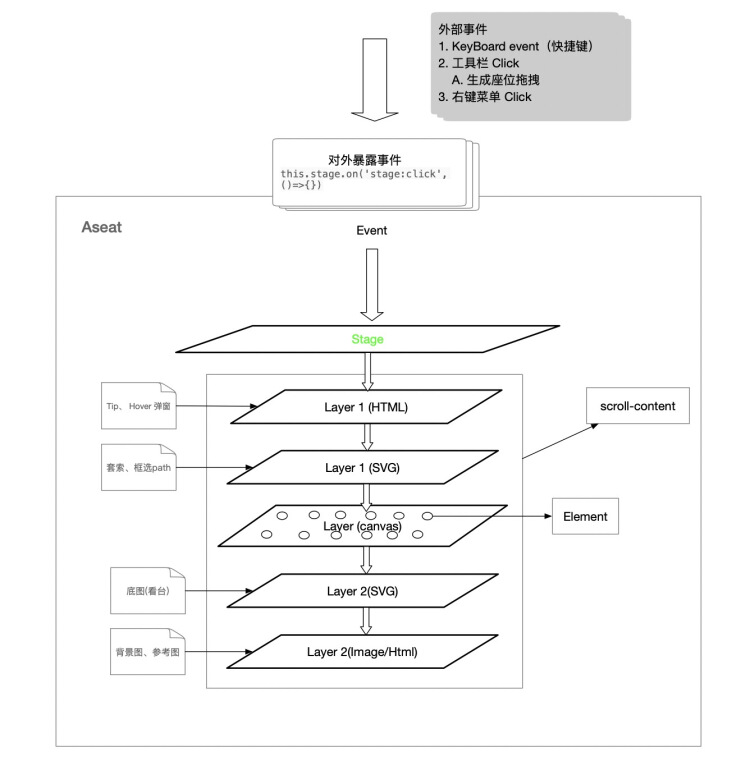
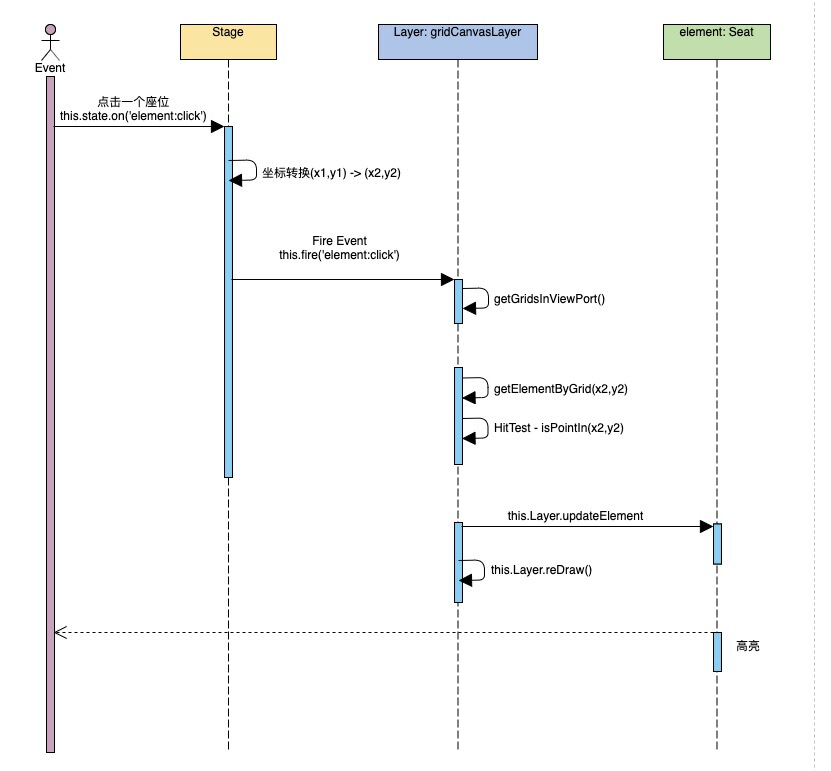 >***以在GridLayer下点击一个座位为demo,事件的流转***
>***以在GridLayer下点击一个座位为demo,事件的流转***
|
Plugin
Plugin设计的初衷是拓展Aseat的能力,Plugin做到可插拔、可拓展、可替换,打造Plugin生态,让基于Aseat为底层的系统,有尽可能多的Plugin供开发者复用,通过搭积木的方式快速满足业务需求,避免重复造轮子。配套有cli 脚手架快速创建Plugin。奥运、大麦累计产出的Plugin 30+ ,如画座工具、选座工具、座位变形、鹰眼图等等。
如下图一个鹰眼图Plugin的demo
import EagleEye from "@alife/aseat-plugin-eagle-eye"
import { Stage, SvgLayer } from "@alife/aseat-core";
const stage = new Stage({...options});
const svgLayer = new SvgLayer({...options})
const eagleEye = new EagleEye({
container: '#aseat-plugin-eagle-eye',
svgLayer: svgLayer,
left: 20,
top: 20,
scrollThrottle: 100,
clickSwitch: true
});
stage.plug(eagleEye);
eagleEye.invoke();
渲染层数据和服务端持久化数据是两套数据,我们要有一个数据代理来解决渲染层和持久化数据格式的握手衔接,我们命名为 Data-Proxy

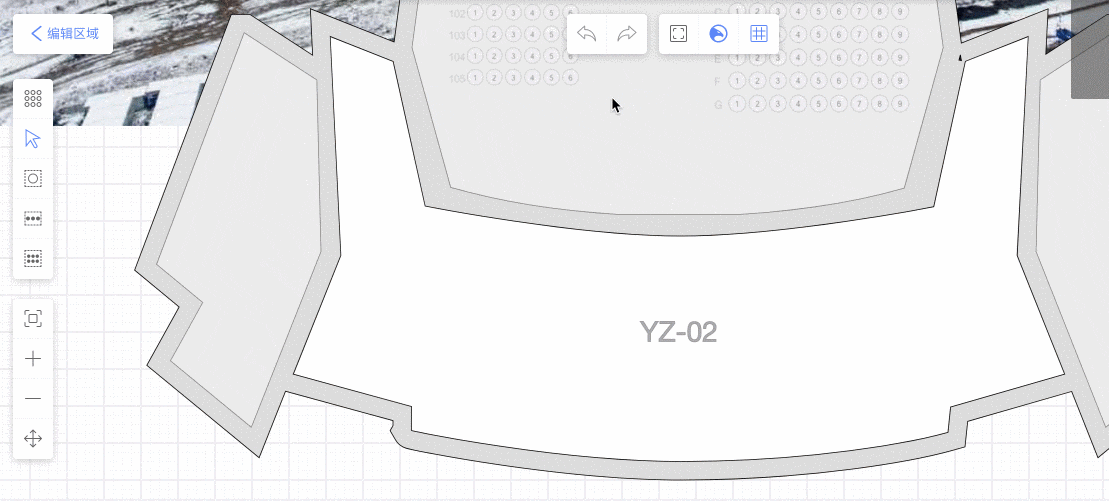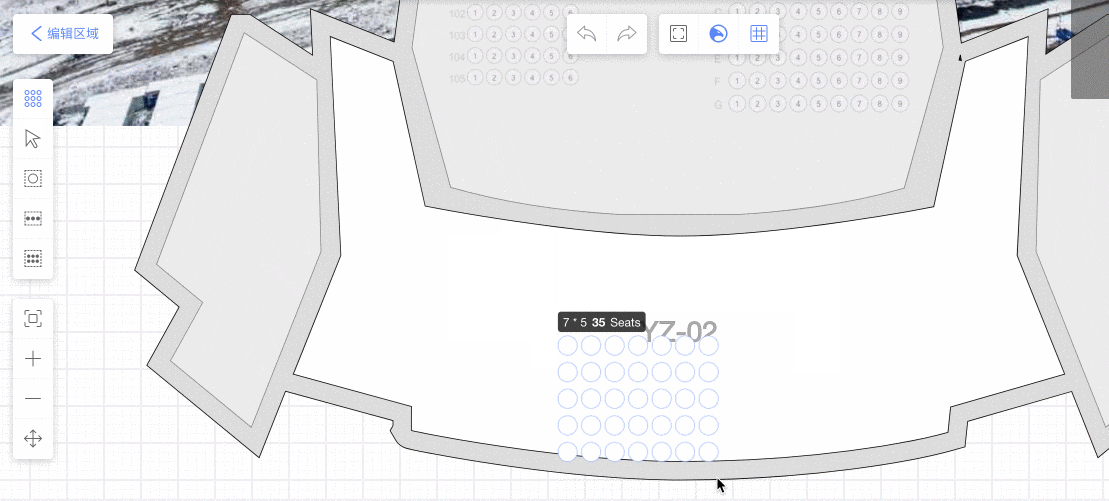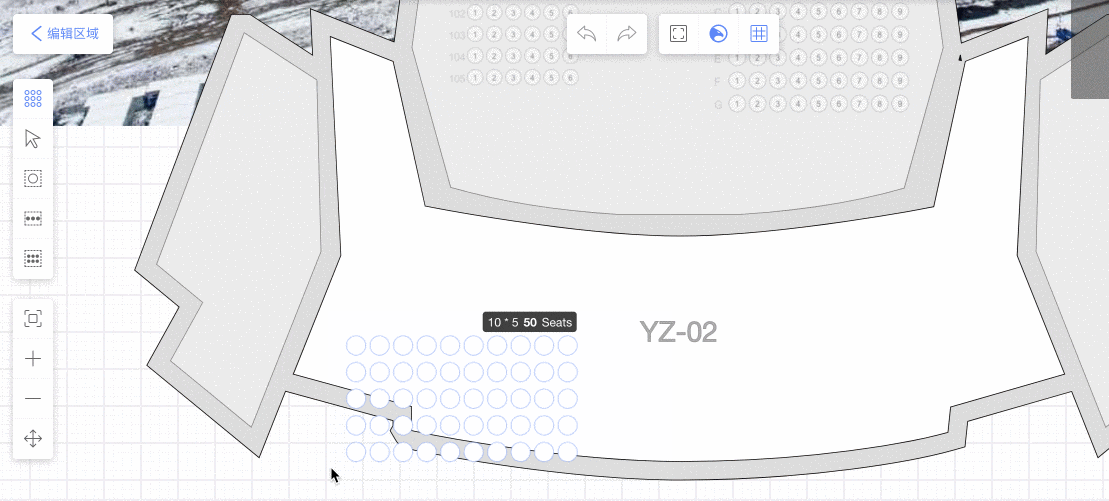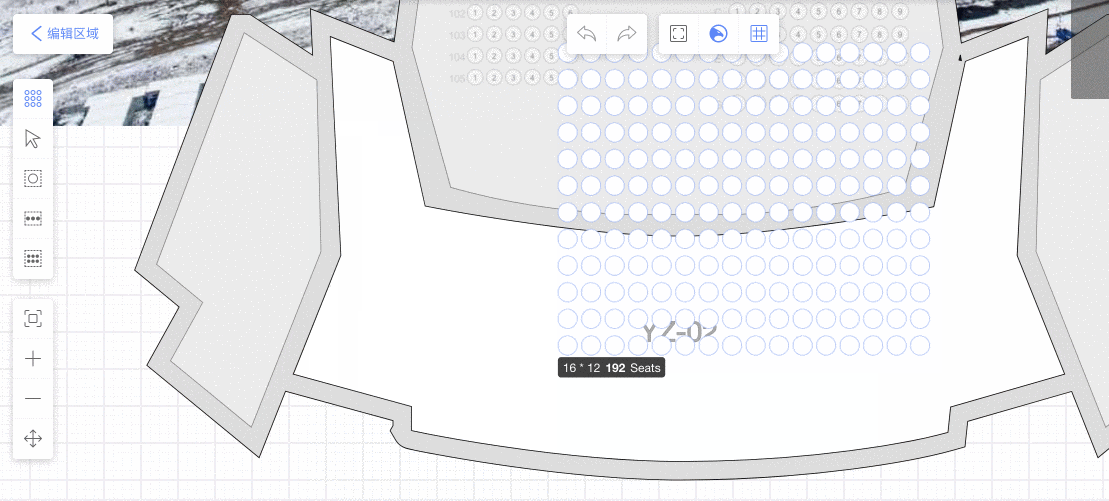
通过画座工具,画满全场馆,通过React层UI 编排座位:定义排号座号规则,座位拖拽、变形。



这一阶段主要做的事就是给每个座位设置票档、Hold Code(禁止售卖、分配给某个大客户)、优先级分配(机选规则设置)
看图可知,这个阶段每天买对花花绿绿的屏幕
同时这个阶段也是将来运营阶段重点操作的步骤,因为策略可能会实时调整。
在这个业务背景下,要对代码、组件进行合理抽象
针对票房规划抽象出的组件级别构架图
先看一下让人头大的CPU负荷
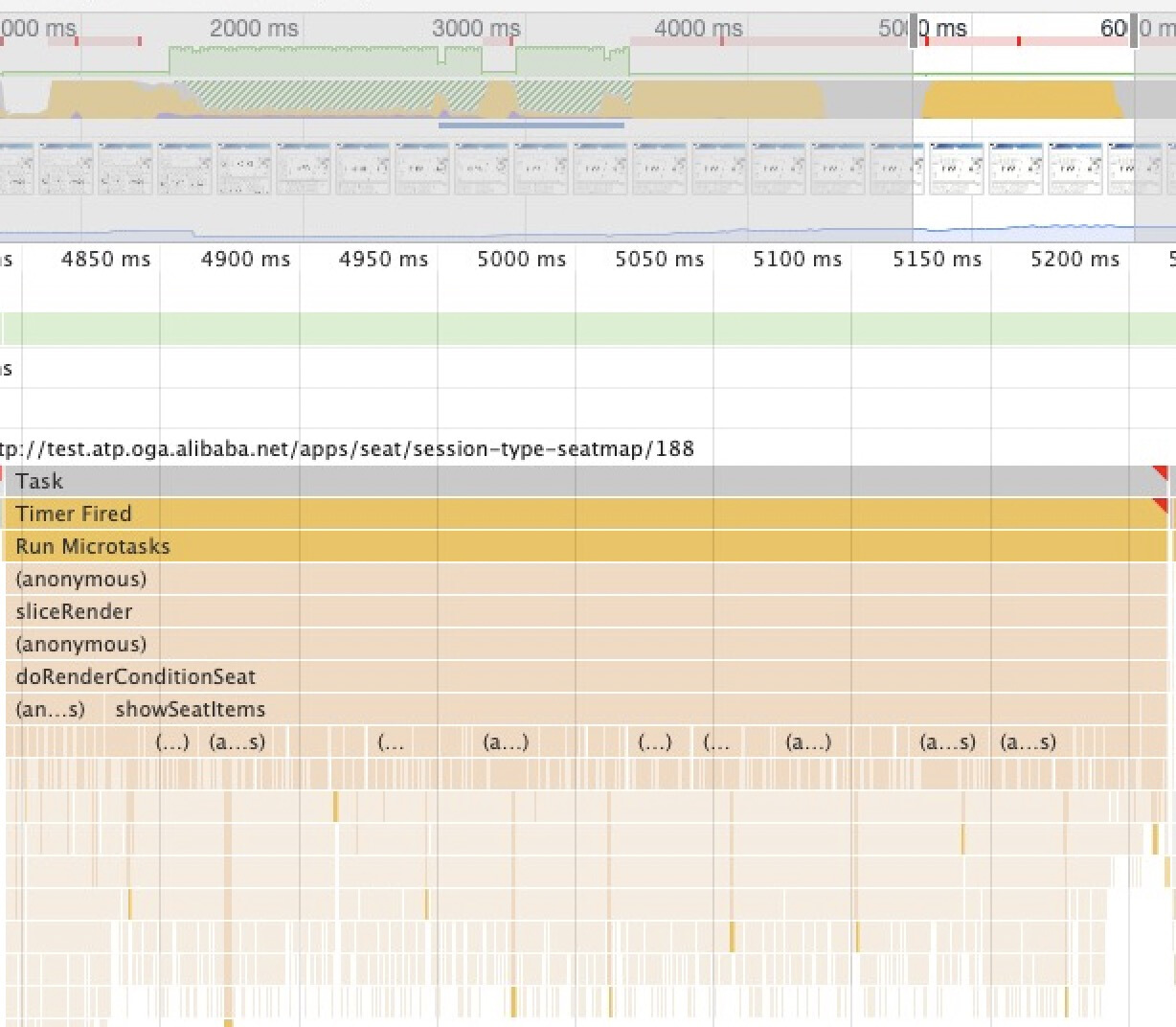
什么原因导致的? 首先需要明确的是,这是一个典型的CPU密集计算场景,以鸟巢为例:8w+的座位,我们以看台纬度获取数据,数据到渲染对象Item的一个映射,也就是new Seat() 的过程中,一个看台平均以1000量级来看,就要执行1000次new Seat()的计算 + 渲染。
可以看到在这一个Task里主线程全部被跑满,全部是扁平的new Seat。
主线程跑满肯定是不行的,计算线程和UI线程互斥,计算线程跑满将会阻塞渲染线程,如果在此时进行UI交互将被阻塞。 其中new Seat的过程中有很多逻辑判断,计算渲染事需要的数据,此过程中会产生很多Hot Object,这一个过程我们也经历过多次优化,比如禁止解构对象,数组赋值不用循环,全部采用下标直接赋值,一些计算采用位运算等等,但是优化后效果不明显,还是避免不了计算量大了之后的问题。
对此还是采用策略级的手段来达成优化的目的
方案一:切片(空间换时间)
降纬计算任务,把「看台」纬度切成「排」纬度,由一个任务队列调度任务,降低每一个Task的计算负荷,代价是时间变长。
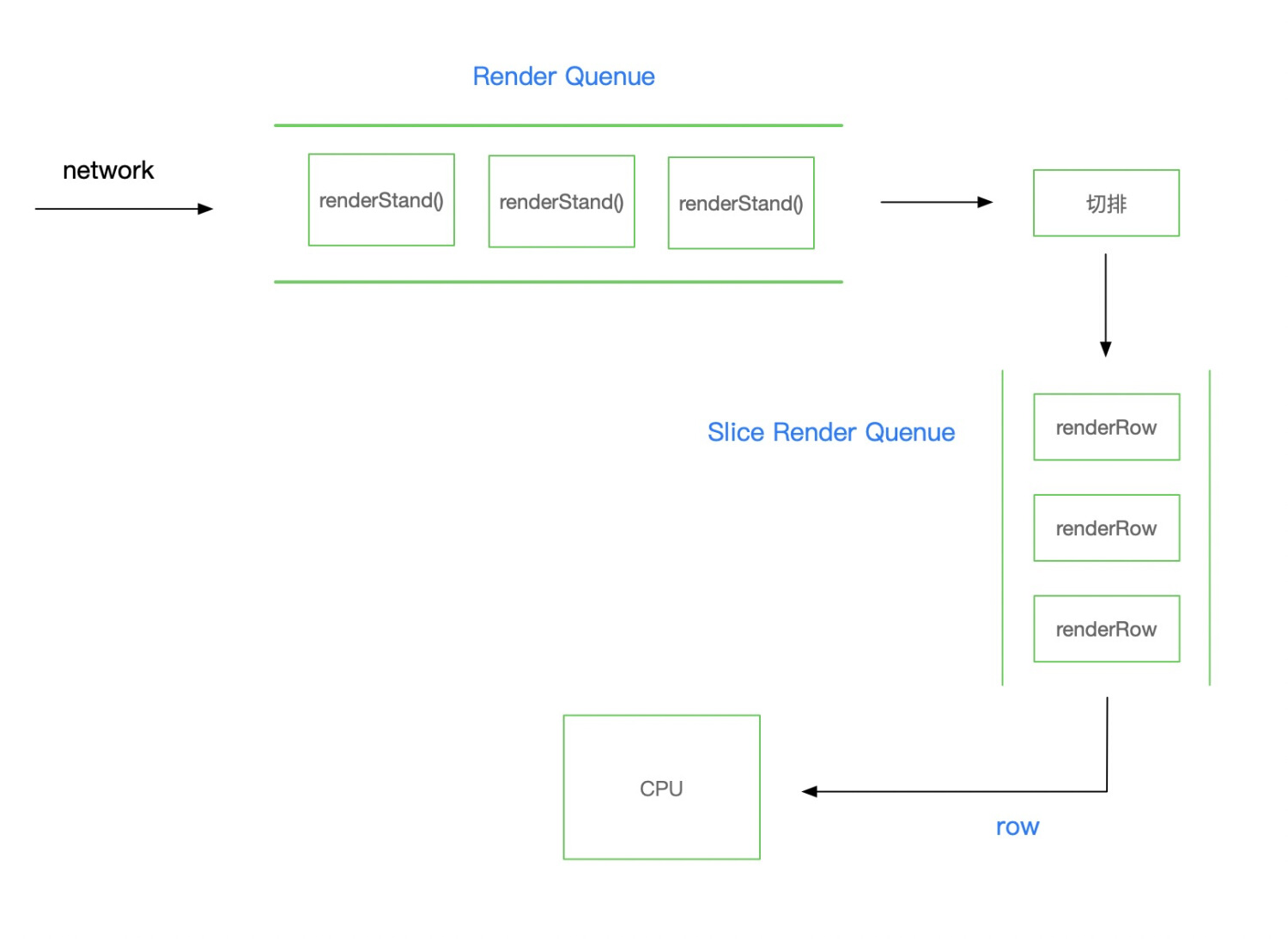

方案二:worker 异步计算,多worker 并行计算,主线程只负责渲染。
切片+队列的方式是解决了计算和渲染冲突的问题,但是毕竟是“时间换空间”,需要用户等的时间变长了,慢,还能不能进一步优化?web worker的作用,就是为了 javascript 创造多线程环境,将一些计算任务分配给woker后台运行,主线程继续运行,两者互不干扰。等到worker线程完成计算任务,再把结果返回给主线程。

如图:1000个座位的onMessage 序列化耗时 44.27ms。
该过程是主线程和worker线程通信的开销,但是主线程不再进行任何计算,所有计算已经在worker中处理好,主线程只需要挂载protoType,然后render
可以看到多个worker同时进行计算任务,还是由一个任务调度分配任务

回头看上面主线程的计算任务:

这是1000个座位创建时的耗时 (canvas 2d)
首先,因为canvas 2d 在浏览器端是以指令为单元向skia图形库发出渲染指令进行渲染的,调用的都是skia暴露出来的API,而这个指令还要在CPU进行更复杂的计算才交给GPU渲染,并且因为是CPU调用,可以理解为同步。换句话说,2d封装的指令更上层,上层即使做了cache之类的优化,也无法优化下层渲染行为。而webgl的渲染会更高效总结最主要的原因:gl 可以进行批处理操作,并且对图形指令的计算在GPU内完成,且GPU更擅长此类操作。
gl在绘制一个图形时,执行流程大概时这样的:
现在再回到我们绘座的场景,业务上每次操作是以看台为粒度大约1000个座位进行操作,每个座位由背景、边框、编号、角标四个元素构成,即每次绘制规模为4000个图形,而每个图形都非常简单。
现代浏览器使用gpu对canvas2d加速,调研4000次fill api, 将会触发4000次的calldraw, 开销都花在,内存copy的io、gpu的渲染管线调度,而不是在真正在渲染上。
由于特定的场景下,可以利用 ANGLE_instanced_arrays 来实现一次 calldraw,渲染多个元素。但是这个方法不是万能的,为什么可以同时渲染多个元素,是因为只能用一个shader,不能切换。不过在绘座的场景下,我们也有解法:用「纹理」来解决多种图形,利用全部可枚举的图形拼成一个雪碧图,在渲染过程中 根据雪碧图中的位置获取像素值即可。
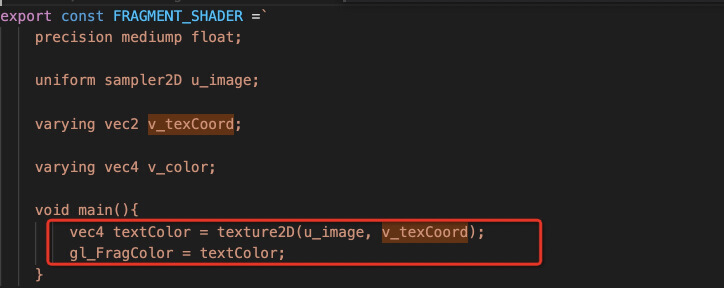
但这里又引入了另一个限制:相同的形状只能绘制相同的颜色,但实际的绘座场景下会出现渲染的图形可能是彩色的图标,也有可能是形状相同,但颜色不同的图形,这个限制显然完全不符合需求。 如何满足用一个shader同时支持技能绘制彩色图标、又能设置图形的颜色?
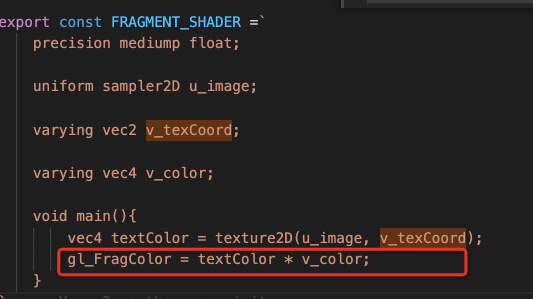
这里我们使用了一个巧妙的办法,添加一个座位的颜色属性,我们将从纹理拾取出来的颜色与座位的色值做乘法(webgl中的颜色值范围都归一到[0,1]) resultColor = textureColor * seatColor [ r1, g1, b1, a1 ] * [ r2, g2, b2, a2 ] = [ r1r2, g1g2, b1b2, a1a2 ] 假设纹理中的颜色为1 ,乘后就得到座位的色值: resultColor= 1 * seatColor = seatColor 。 反之,假设座位的颜色为1, 得到纹理的色值: resultColor = (textColor * 1) = textColor。
这样如果想渲染一些定制的彩色图标,将座位的颜色设置为白色。 所以我们将代码做如下改动即可。
ASeat中创建一个新的renderer GLRender ,定义它的渲染流程为:
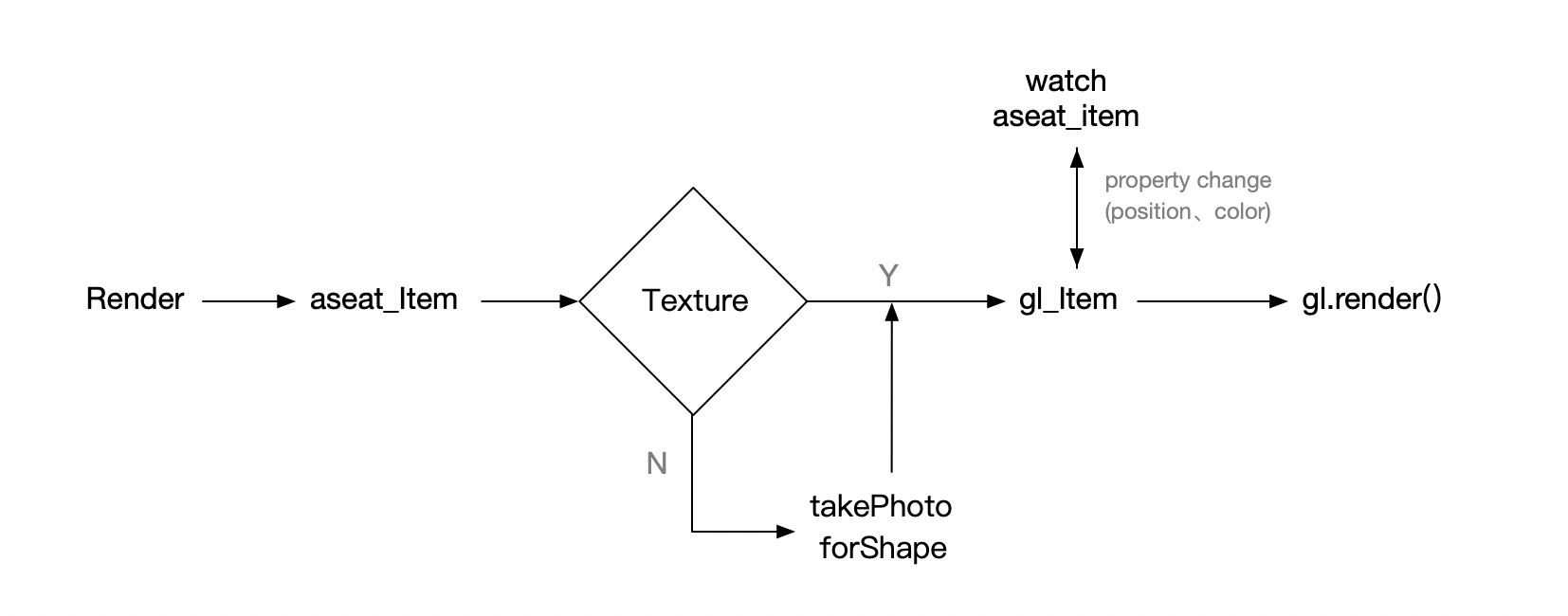
其中刚才提到的纹理雪碧图要在这个Render中预处理
对于Aseat这个场景下,纹理很简单,将各种shape绘制到AABB的boundingBox大小canvas中,所以纹理里全是矩形的Image,这样在shader转换顶点数据时将变的很简单。

创建纹理过程:

根据Item所对应的不同shape做快照(itemShapeImg),这里需要注意的是对于gl来讲fill 和stroke是两个纹理,所以要对Item精细的拆分,也就是说Item和纹理是一对多的关系。

渲染过程:
计算Item所需要的纹理;因为Seat为Group元素,对应多个绘制指令,这里要拆分到具体每一个指令级别的Item。维护一个离屏 Texture canvas,随着渲染同步向这个canvas drawImage。
Item 坐标转换,grid position -> 单个canvas position
同步 glElement 坐标、颜色信息
调用 glRender()
特殊处理:
在grid canvas场景下,2d Context 和 canvas 是一一对应的关系,每个canvas有自己的2d context,但是在gl render的场景下,因为gl render 不允许也不能够创建多个上下文,所以这里还要特殊处理:多个canvas 共享一个glContext 通过drawImage 渲染到grid canvas中


gl render 结果

